WindowsとLinuxでは使用している文字コード、改行コード、ファイル名の規則が以下のように異なります。日本語名のファイルをWindows から Linuxへ、LinuxからWindowsへ転送すると通常は文字化けを起こしますが、最近はソフトウェアが自動で変換を行ってくれるのでユーザが心配をする必要はありません。ファイル内の文字コードもエディターが文字コードを自動判別して表示してくれるので、最近は気にする事が少なくなってきましたがエンジニアとして対処方法などは知っておく必要はあるでしょう。
Windows Linux
ファイル名の文字コード S-JIS UTF-8
ファイル内の文字コード S-JIS UTF-8
改行コード CR(\r\n、0x0D0A) LF(\n、0x0A)
ファイル名 大文字小文字区別なし 大文字小文字区別※CP932は、S-JISに機種依存文字を追加したWindows独自の文字符号化方式です。Windows のGUI上ではANSIと表示されている。
※Windows の WSL 上では UTF-8
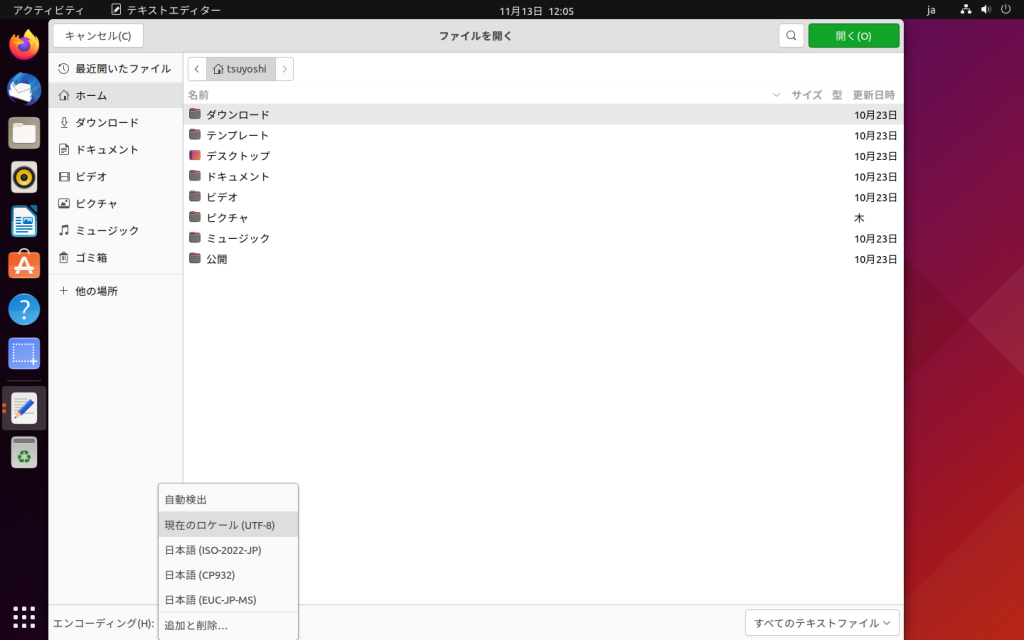
まずは、GNOMEデスクトップの標準テキストエディタgeditは、ファイル選択時に「エンコーディング」項目を選択する事が出来ますが、デフォルトでは自動判別になっているので意識しなければ分かりません。もし確実にWindowsユーザに文字化けしないテキストデータを送りたいのであれば、保存時に「名前を付けて保存」を選択すれば、「エンコーディング」をCP932、「改行文字」をWindowsに設定して保存しなおせば良いでしょう。
コマンドで変換したい場合はnkfが便利です。デフォルトではインストールされていないのでインストールして以下のように実行します。
$ sudo apt install nkf
-s S-JIS -Lw CR改行 に変換
$ nkf -s -Lw sample.utf-8.txt >sample.sjis.txt
-w UTF-8 -Lu LF改行 に変換
$ nkf -w -Lu sample.sjis.txt >sample.utf-8.txt Windows の標準テキストエディタはメモ帳です。かつてLinuxで作成したファイルはメモ帳で開くと文字化けしていましたがWindows 11のメモ帳はgeditと同じように文字コードを自動判別して開いてくれます。保存時もgedit同様に「名前を付けて保存」を選択して「エンコード」を選択すれば良いでしょう。しかしメモ帳は使用している改行コードはウィンド右下に表示されていますが、改行コードを変換する事が出来ません。正しく表示されているなら気にする必要はありませんが、エディターによっては改行コードが異なると文字列が一行全てに表示されてしまうといった問題が生じる事もあるので適宜変換して運用して下さい。
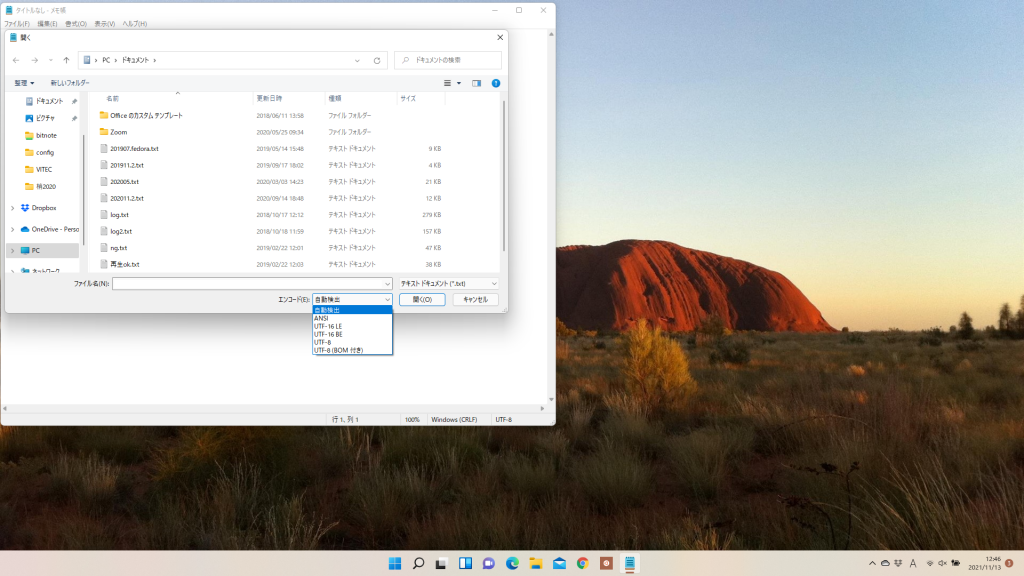
※BOM : 先頭の数バイトにUnicodeのデータであることやどの種類の符号化形式を採用しているのかを判別する為のデータ
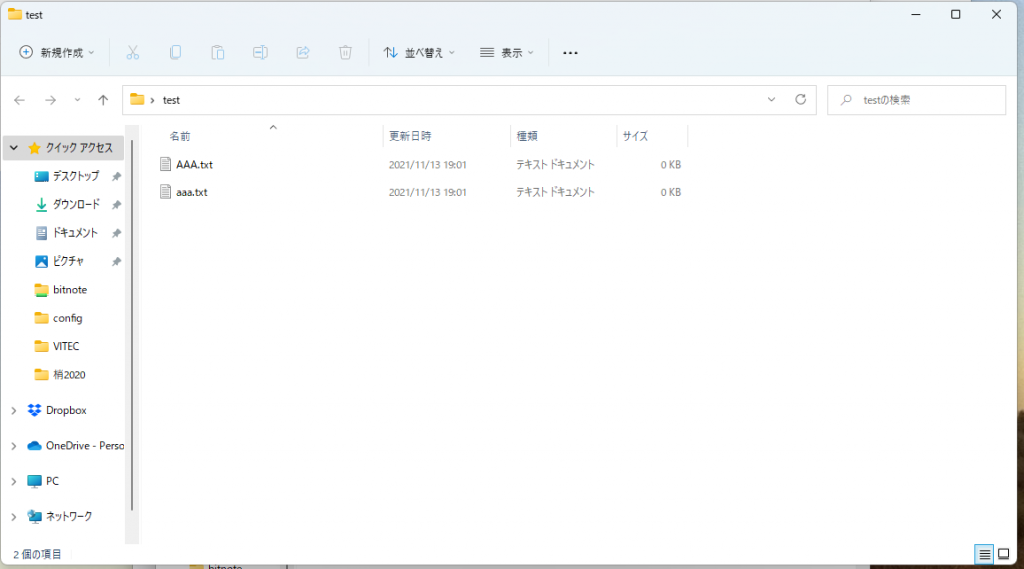
どうしてもWindows上でファイル名の大文字と小文字を区別したい場合は、コマンドプロンプトでWindowsのファイルシステムを管理するコマンドfsutilを使って以下のように実行すると指定したディレクトリ上だけ大文字と小文字の区別が有効になります。空のディレクトリしか有効に出来ないので新規にディレクトリを作成してからコマンドを実行して有効化します。
c:\Users\hoget\Desktop\test>fsutil.exe file SetCaseSensitiveInfo . enable
ディレクトリ c:\Users\hoget\Desktop\test の大文字と小文字を区別する属性が有効になっています。
c:\Users\hoget\Desktop\test>fsutil.exe file SetCaseSensitiveInfo . disable
ディレクトリ c:\Users\hoget\Desktop\test の大文字と小文字を区別する属性が無効になっています。通常は大文字、小文字同一のファイル名を作成できない。
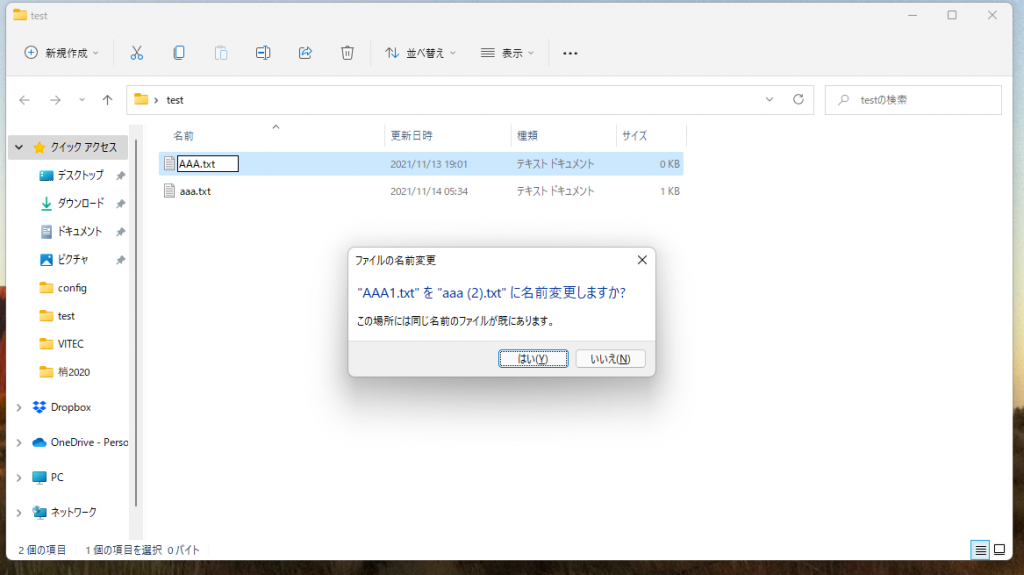
有効化後、大文字、小文字同一のファイル名が作成できる。